
 |
 |
 |
 |
 |
Final Test Construction |
Items in the final pool were ordered based on difficulty parameter estimates (ranging from b = -2.83 to 3.02) and proportion of correct responses by age. The final test was constructed with specific starting and stopping rules to ensure only necessary items are presented (instead of presenting the entire test) and to correspond with the examinee’s receptive vocabulary acquisition. As described in chapter 3, Administration and Scoring, the Screener items aid in identifying a suitable starting point (i.e., basal item). Test items gradually increase in difficulty as examinees progress through each form, and the test stops when a ceiling is reached (defined as five errors in ten consecutive items). The test’s starting and stopping rules were derived by empirical data analysis based on performance of the English Speaker and English Learner normative samples, along with binomial probability distributions to account for successful performance due to chance.
Creation of Screener Items
Screener items (common across Forms A and B; presented prior to test items) were investigated using the same criteria as the test items. The item functioning standards for the Screener items were more stringent than for regular test items, as Screener items are critical to determine the appropriate point at which the examinee should begin the test. In particular, items with low item information or any evidence of DIF were immediately removed from the Screener item set, because such items would not provide meaningful information to determine appropriate starting points for examinees. In addition, a 3-parameter logistic (3PL) dichotomous IRT model was fit to the Screener items in order to estimate the guessing parameter. Items with a high degree of guessing (i.e., c > .50) were removed from the Screener set, given that answering correctly by chance could inadvertently allow examinees to begin the test at a point that is too difficult for them. Thirteen items were retained after a review and analysis of the original 20 Screener items; those items were then grouped into five sets of two or three items, based on similar empirical item difficulty values. Examinees must respond correctly to all items within a Screener set in order to advance to the next Screener set; otherwise, the Screener will end. The starting point on the test is determined by the last Screener item that the examinee responded to correctly.
Performance on the Screener sets was evaluated using the English Speaker and English Learner normative samples separately. The IRT-based estimate of receptive vocabulary ability was compared for individuals who correctly responded to all items in each Screener set. For each set, the average ability level of successful respondents was then matched to one of the test items with a corresponding level of difficulty to determine suitable starting points based on Screener performance. For consistency, starting points were selected to be common items across the two forms. The basal set (defined, for development purposes, as nine correct out of the first ten attempted items) was based on examination of the binomial probability distribution and was selected to reduce the possibility of advancing simply by chance. To verify that the starting points determined by the Screener were appropriate, the proportion of individuals who successfully established a basal set was examined. Results showed that, within both normative samples and on both forms, 98% of individuals correctly responded to at least nine of the first ten items following their assigned starting point (as determined by the Screener), confirming that the starting points as determined by the Screener served as a suitable placement.
Age of the examinee was then taken into account in the structure of the Screener. The proportion of individuals within each age group who passed each Screener set was examined to guide the decision to permit certain age groups to attempt certain Screener sets, such that individuals would not advance to Screener sets (and subsequent test items) that are beyond the typical ability for their age group (i.e., harder than 90% correct, on average, for a given age group). Individuals attempted Screener set items (up to a limit, as determined by their age); if they correctly answered all the items, the test would begin at the highest corresponding starting point.
To illustrate the age-related limits of the Screener, consider the following example (also depicted in Figure 6.4). A 7-year-old is first presented with Screener Set A (“tub,” “pasta,” and “pills”). If one or more items in this set was answered incorrectly, the Screener items will stop and the test will begin at item 1 (the easiest item, “baby”). However, if all items in Set A were answered correctly, Screener Set B (“fresh” and “equal”) will be presented. If all the items on both Set A and Set B were answered correctly, the examinee will begin the test at the item “sit” (i.e., item 25; the examinee bypasses the first 24 items, or 14% of all items on the test).
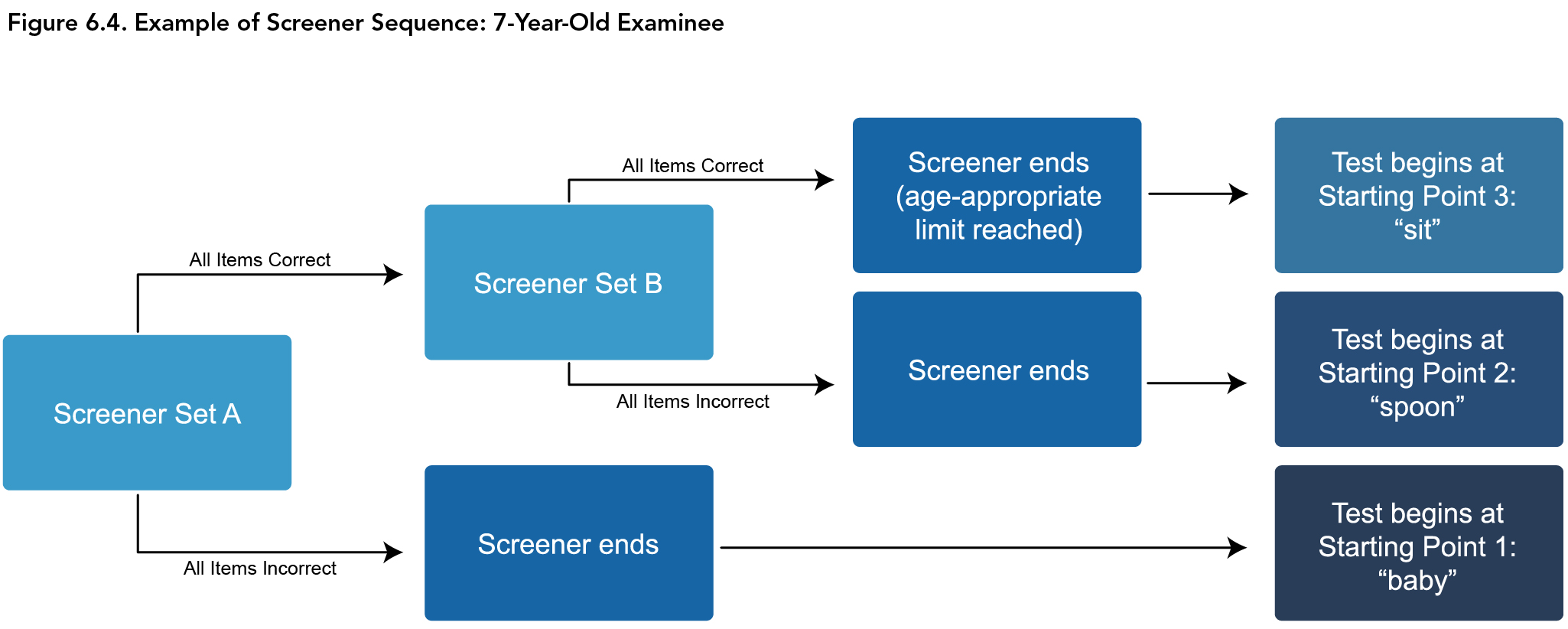
Since all items on the test are ordered by difficulty and the starting item “sit” is at a lower difficulty level than the Screener Set B items “fresh” and “equal,” it can be assumed that the examinee would be able to correctly answer all the corresponding test items that are at a lower difficulty level than the item “sit.” Credit will be given to all the items on the test that are easier than “sit” in the calculation of the raw score. Alternatively, if all items on Screener Set A were answered correctly, but one or both items on Screener Set B were answered incorrectly, the examinee will be placed at the starting item corresponding to Set A (“spoon”), and will bypass the first 9 items on the test, or, 5% of all items. Note that the six possible start points are common across Forms A and B. For more details about the Screener items, their corresponding starting points on the test, and which age groups are allowed to progress to which Screener sets, see Special Topic: How the Screener Works in chapter 3, Administration and Scoring.
Creation of Parallel Forms
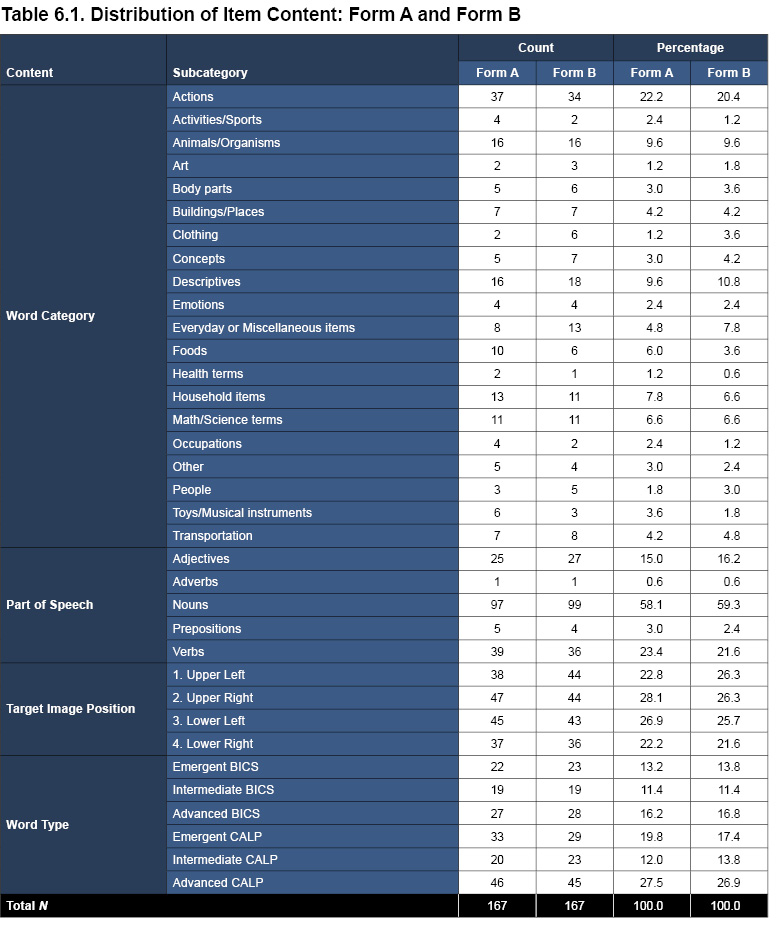
To ensure comparability between forms, every fifth item appears on both forms, in alignment with the recommendation that at least 20% of the items be common across alternate forms of a test (Kolen & Brennan, 2014). In addition, due to the limited number of extremely easy test items available, the two forms share the first 10 items to maximize measurement precision in the very low ability range. Items throughout the rest of the test were assigned to either Form A or Form B, matching item difficulty values as closely as possible (for both Form A and Form B, Mdifficulty = -0.31 and SDdifficulty = 1.02). The final pool of 292 items was split onto two forms with 167 items on each (including the shared or common items already described). Additional consideration was given to balance the frequency of each part of speech, word type (i.e., BICS and CALP), position of the target image, and word category across the two forms (see the chapter 4, Scores and Interpretation, section, Step 4: Examine Performance by Vocabulary Type, for more details in the interpretation and application of the various word categories). A summary of the two forms is provided in Table 6.1.
| << Standardization Phase | Chapter 7: Data Collection Procedures >> |